对象模型
分层架构是后端系统的标准实践。不同层级之间需要传递数据,这些数据的组织方式直接影响系统的可维护性和业务逻辑的表达能力。理解各种数据对象的定位和职责,是构建清晰架构的基础。
层间数据对象
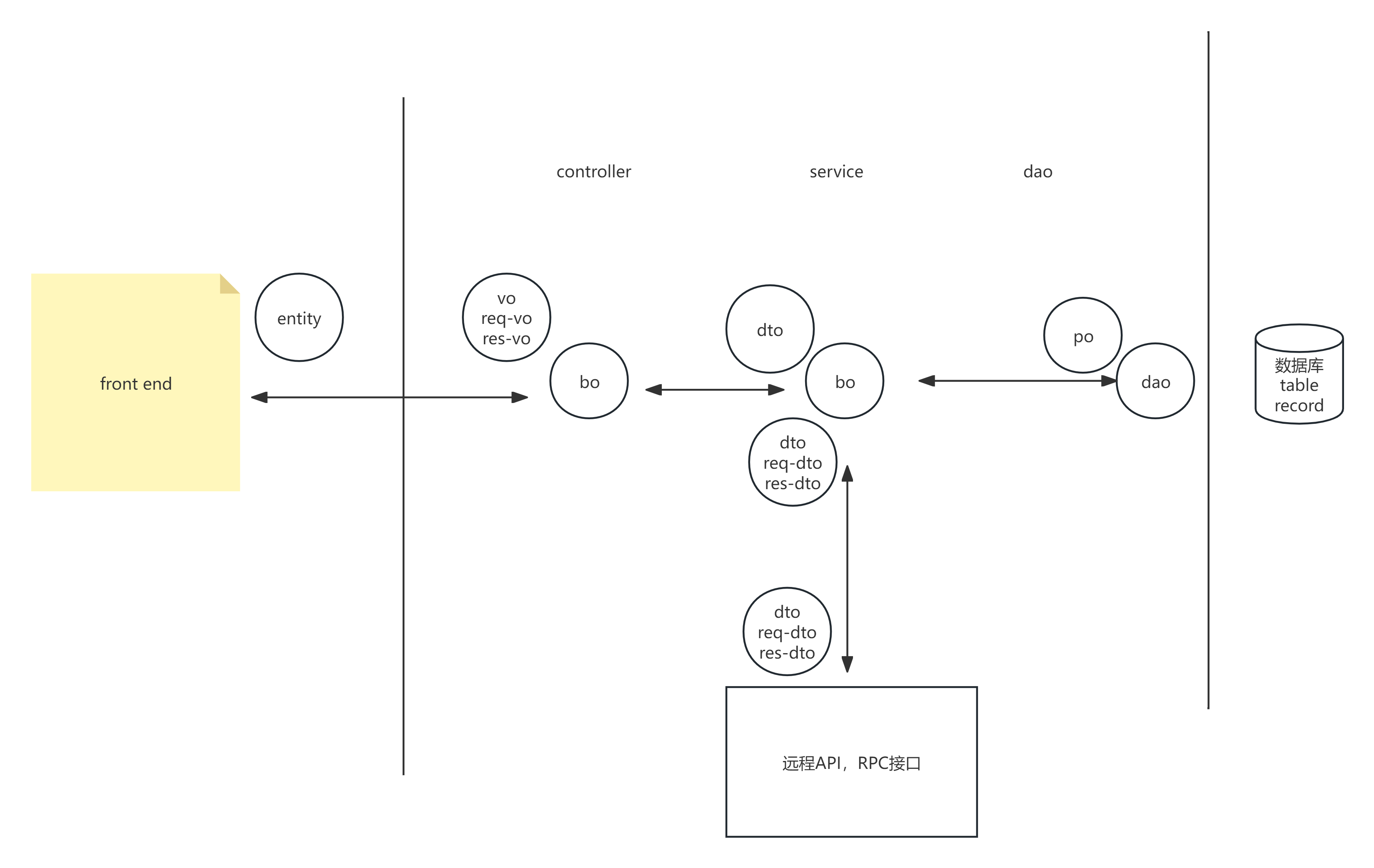
PO(Persistent Object)持久化对象
PO 直接代表数据库表中的数据,与数据库字段一一对应。它是纯数据容器,不包含业务逻辑方法。PO 的唯一职责是与数据库表结构同步,当 ORM 框架映射数据时,PO 作为数据载体存在。
从设计角度看,PO 应该保持"贫血"状态,不包含任何业务行为。这种设计确保了 PO 的纯粹性:它只是数据存储格式的代码表示,不承担任何业务职责。当数据库表结构变化时,PO 的同步修改是唯一需要做的工作。
DAO(Data Access Object)数据访问对象
DAO 负责数据库的读写操作,是数据访问层的入口。DAO 是面向 PO 进行操作的,它的方法通常是 CRUD(增删改查)操作的封装。DAO 可能持有状态(如数据库连接),但本身不包含业务数据。
DAO 的价值在于隔离数据访问细节。上层代码不需要关心是 MySQL 还是 PostgreSQL,不需要关心 SQL 语句的构造细节,只需要调用 DAO 的方法即可完成数据操作。这种隔离使得替换数据库或优化访问策略时,只需要修改 DAO 层的实现。
ORM(Object-Relational Mapping)对象关系映射
ORM 是更高层次的抽象,它将数据库表映射为对象,将 SQL 操作映射为对象方法调用。ORM 的封装程度非常高,开发者可以用操作对象的语法来操作数据库,将复杂的数据库访问操作屏蔽在框架内部。
ORM 的优势在于开发效率,但代价是性能和可控性的损失。复杂的关联查询、批量操作、性能优化在 ORM 层面往往难以精确控制。在性能敏感的场景,直接使用 DAO 或原生 SQL 可能是更好的选择。
DTO(Data Transfer Object)数据传输对象
DTO 用于跨进程或跨层传输数据。在微服务架构中,服务之间通过 DTO 传递数据;在单体应用的分层架构中,Service 层与 Controller 层之间通过 DTO 传递数据。
DTO 的设计应该考虑到传输效率,只包含必要字段,避免传递不必要的数据。DTO 是纯粹的值对象,不包含业务逻辑。在实践中,为了避免层间转换的开销,许多项目会简化 DTO 的使用,甚至在简单场景下直接使用 PO 作为 DTO。但业务复杂后,这种简化会成为架构腐化的起点。
BO(Business Object)业务对象
BO 包含了业务逻辑和业务状态,是领域模型的核心。BO 中的方法体现了业务规则和行为,如"计算订单总价"、"判断用户是否可以下单"等。BO 可能是无状态的服务对象,也可能是有状态的实体对象。
BO 是充血模型和贫血模型的分水岭。在贫血模型中,BO 只是数据的容器,业务逻辑散落在 Service 层;在充血模型中,BO 是业务逻辑的载体,数据和行为被封装在一起。
VO(View Object)视图对象
VO 用于前后端交互,是 API 接口的数据契约。VO 分为请求 VO(Req)和响应 VO(Res),前者定义前端需要提供的参数,后者定义后端返回的数据结构。
VO 的设计应该考虑前端的使用便利性和后端的实现简洁性。Req VO 需要包含数据校验注解,Res VO 需要考虑序列化格式和字段过滤。在实践中,为了减少定义工作,一些项目会将 VO 和 DTO 合并,但这种合并在业务复杂后会带来维护困难。
领域设计
从 DDD 中迁移过来的两个概念。
贫血模型
贫血模型(Anemic Domain Model)是指领域对象只包含数据,不包含业务逻辑,业务逻辑全部散落在 Service 层。这是 Java 企业级开发中最常见的模式,也是被 Martin Fowler 批评为反模式的设计。
在贫血模型中,PO 或实体类只是数据的载体,所有的业务计算、规则判断、流程控制都在 Service 层的方法中实现。例如一个 Order 类可能只包含 orderId、items、totalAmount 等字段,而"计算订单总价"、"判断订单是否可取消"等逻辑都在 OrderService 中实现。
这种结构的优势在于简单直接。数据与行为分离,符合很多人的直觉认知。Service 层的方法可以灵活地操作多个领域对象,实现复杂的业务流程。对于简单的 CRUD 应用,贫血模型是快速开发的有效手段。
贫血模型的核心问题是领域对象失去了对象的本质。对象应该是状态和行为的封装体,而贫血模型中的对象只是数据结构,不是真正的对象。这种设计导致业务逻辑散落在各处,难以定位和维护。
当业务复杂度增加时,贫血模型的弊端会变得明显。相同的业务规则在多个 Service 方法中重复出现,修改规则时需要同步修改多处。Service 层变得臃肿不堪,成为新的"上帝类"。领域逻辑被淹没在技术细节中,代码难以体现业务意图。
从面向对象的角度看,贫血模型实际上是面向过程的设计。它只是披着对象外衣的过程式编程,没有发挥面向对象的封装、多态等优势。
充血模型
充血模型(Rich Domain Model)是指领域对象包含业务逻辑,数据和行为被封装在一起。这是领域驱动设计(DDD)倡导的实践,也是面向对象设计的本意。
在充血模型中,Order 对象不仅包含数据,还包含 calculateTotal()、canCancel()、applyDiscount() 等业务方法。这些方法操作对象自身的状态,体现了业务规则和约束。Service 层变得很薄,主要负责协调领域对象、处理横切关注点(如事务、日志)。
这种结构的优势在于业务逻辑的内聚。相关数据和行为被封装在同一个对象中,修改业务规则时只需要修改该对象。代码的可读性提高,领域知识通过对象结构得到表达。业务复杂度被分散到多个领域对象中,避免了 Service 层的臃肿。
充血模型的实践难点在于对象生命周期的管理。领域对象需要从数据库加载、在内存中操作、然后持久化回去,这个过程涉及事务、并发、延迟加载等复杂问题。如果处理不当,可能导致 N+1 查询、事务边界模糊、数据不一致等问题。
另一个难点是领域对象与持久化机制的分离。纯粹的充血模型要求领域对象不依赖任何框架,但实际开发中往往需要与 ORM 框架集成。如何在保持领域模型纯粹的同时,兼顾技术实现的便利性,是架构设计需要权衡的问题。
选择与权衡
贫血模型和充血模型各有适用场景。对于简单的 CRUD 应用,贫血模型的开发效率更高,团队学习成本更低。对于业务逻辑复杂、业务规则频繁变化的领域,充血模型能够更好地表达业务知识,提高代码的可维护性。
从演进的角度看,项目初期可以从贫血模型开始,快速验证业务假设。随着业务复杂度增加,逐步将业务逻辑下沉到领域对象,演进为充血模型。这种渐进式的重构比一开始就追求完美的领域模型更加务实。
关键是避免盲目选择。理解两种模型的本质区别和权衡取舍,根据项目的业务特点、团队技能、复杂度预期做出合理选择,这比教条地遵循某种"最佳实践"更有价值。