Transformer
在深度学习序列建模的发展历程中,Transformer 的出现是一个转折点。2017 年 Google 发表《Attention is All You Need》时,transformer 架构主要用于机器翻译的任务,很多人并未意识到这将成为现代大语言模型(LLM)的基石架构。
回看 RNN/LSTM 时代的痛点——串行计算导致的训练效率低下、长距离依赖的梯度消失问题,Transformer 用一个优雅的设计彻底解决了这些难题:完全抛弃循环结构,让序列中每个位置都能直接"看到"其他所有位置。甚至从结构上看,transformer 比 LSTM 还要更加简洁,多数部分是重复结构。
了解 Transformer 架构原理参看知乎文章:Transformer模型详解。
从 seq2seq 到注意力机制
Transformer 的思想渊源可以追溯到 seq2seq 模型。早期的序列到序列任务(如机器翻译)使用编码器-解码器架构:编码器将输入序列压缩成一个固定长度的向量,解码器从中生成输出序列。但这种设计存在明显问题——无论输入多长,最终都被压缩成一个向量,信息瓶颈严重。
注意力机制的引入缓解了这个问题。解码器在生成每个词时,不再只依赖固定的上下文向量,而是可以"关注"输入序列的不同位置。这让人联想到人类阅读时的做法:理解一个复杂句子时,我们会反复回看前后相关的词,而不是一次性记下所有信息。
但那时的注意力机制仍建立在 RNN 之上,计算效率问题并未解决。Transformer 的核心洞察是:既然注意力机制如此有效,为什么不直接用它来建模序列关系,而保留 RNN 的递归结构呢?
整体架构设计
Transformer 采用编码器-解码器架构,输入序列经编码器处理为语义表示,再由解码器生成输出。编码器和解码器各由 6 层(原论文配置)相同的模块堆叠而成,每层包含三个核心组件:多头自注意力层、前馈全连接层(FFN)、残差连接与层归一化。
编码器的任务是理解输入序列,输入序列由需要翻译的原文经过 embedding 之后得到。每层的多头自注意力让序列中每个位置都能与其他所有位置交互,捕捉词之间的依赖关系;前馈网络则负责对每个位置的表示进行非线性变换,增强表达能力。编码器的处理是并行的——所有位置同时处理,输出是一组与输入等长的上下文表示向量。解码器除了自注意力外,还有一个编码器-解码器注意力层(Cross-Attention),用于在生成时关注输入序列的相关部分。
解码器承担生成任务,采用自回归方式逐个输出 token,需要输入的序列由需要进行翻译的目标文本经过 embedding 之后得到。它的自注意力层使用掩码机制防止位置关注到后续信息,这是为了保证训练和推理的一致性——推理时我们无法看到"未来"的词,训练时也要模拟这个约束。编码器-解码器注意力层让解码器在生成每个词时,能够回顾编码器处理过的输入表示。形象地说,编码器负责"读懂"输入,解码器负责"写出"输出,而 Cross-Attention 是两者之间的桥梁。
![]()
自注意力机制
QKV
自注意力是 Transformer 的核心创新。给定输入词向量矩阵 X(n 个词,每个词 d 维),通过三个可学习的投影矩阵生成 Query、Key、Value:
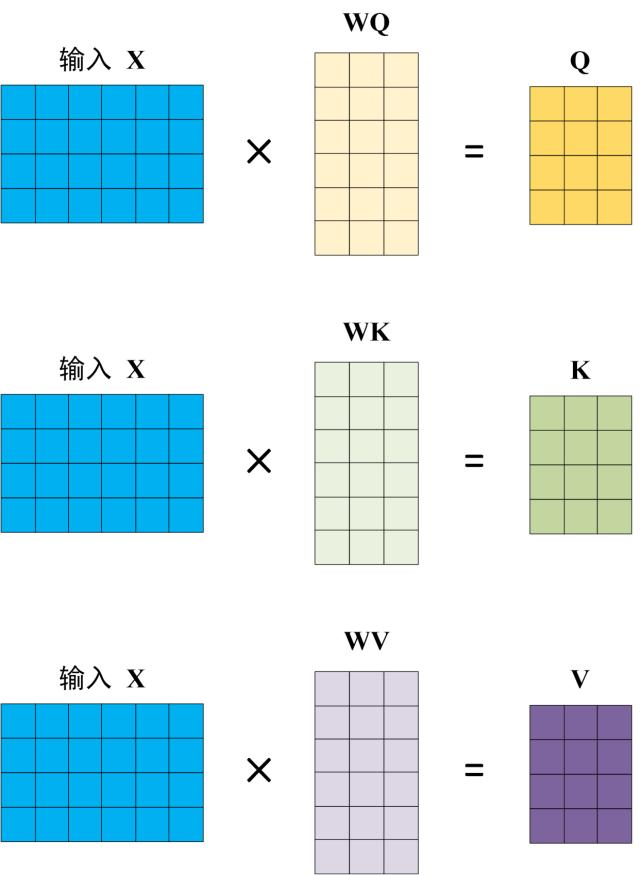
Q K V 都是通过输入的词向量和各自的参数矩阵点乘得到,初期这三者的参数矩阵均为随机初始化。符合自注意中的自的概念。
注意力计算的核心公式是:
这个公式的直观理解是:QK^T 计算每对词之间的相似度,得到注意力分数矩阵;除以
可以把 Q、K、V 理解为检索系统中的三个角色:Query 是"我想找什么",Key 是"有什么标签可以匹配",Value 是"实际内容"。每个词同时扮演三种角色——既发出查询,也作为被查询的目标,最终得到的是所有词对其的"关注程度"加权后的信息聚合。通过自注意机制,模型可以分析一个句子中的各个词语之间具有怎样的关系,充分地理解每一词的语义,此即为自注意的含义。
举例来说,处理句子 "The cat sat on the mat" 时,"sat" 这个词的 Query 会与所有词的 Key 计算相似度。由于主谓关系,"cat" 会得到较高权重;由于动宾关系,"mat" 也会有显著权重。这样 "sat" 的最终表示就融合了主语和宾语的信息。
缩放因子
多头注意力
单个注意力头只能捕捉一种类型的关系。自然语言中的依赖是多样的:语法关系(主谓一致)、语义关系(近义、反义)、共指关系(代词指代实体)等。多头注意力通过多组独立的 Q、K、V 投影,让不同的头专注于不同的模式。
原论文使用 8 个头,每头维度 64(总维度 512)。各头计算完成后,拼接起来再经过一个线性变换融合。这种设计类似于计算机视觉中的多通道卷积核,每个通道学习不同的特征模式。
从工程实践来看,头的数量和维度之间存在权衡。头数过多会增加参数量和计算开销,但能捕捉更细粒度的模式;头数过少则可能损失表达能力。现代模型通常将头数设为 8-32,具体取决于模型规模。
三种注意力机制
Transformer 中实际上有三种不同的注意力机制,虽然计算公式相同,但 Q、K、V 的来源和语义完全不同。
- 编码器自注意力中,Q、K、V 都来自编码器自身的输入(同一层的前一层输出)。每个位置都能看到所有其他位置,没有掩码限制。这种"全透明"的设计让编码器能够充分捕捉输入序列中任意两个词之间的关系。以机器翻译为例,编码器处理英语句子"The cat sat on the mat"时,"sat"的 Query 会与"cat"(主语)和"mat"(宾语)的 Key 计算高相似度,从而融合主谓宾信息到自身的表示中。
- 解码器自注意力中,Q、K、V 同样来自解码器自身的输入,但关键区别在于使用了因果掩码——每个位置只能看到之前的位置。这是为了保证自回归生成的合理性:生成第 t 个词时,只能依赖前 t-1 个词,不能"偷看"后面的词。训练时通过将未来位置的注意力分数设为负无穷来实现,推理时则是自然满足。这就像人类写作,我们只能根据已经写下的内容决定下一个词,无法依赖还未写的内容。
- 编码器-解码器注意力(Cross-Attention)中,Q 来自解码器,K 和 V 来自编码器的输出。解码器在生成每个词时,通过 Q 向编码器发送"查询",寻找输入序列中的相关信息,然后通过 K-V 检索得到对应的内容。继续以翻译为例,解码器生成中文"猫"这个字时,Q 会查询编码器处理过的英语表示,发现与英语"cat"的 K 匹配度高,就从对应的 V 中提取信息,帮助正确生成翻译。
这三种注意力的分工明确:编码器自注意力负责"理解输入"——让输入序列内部充分交互;解码器自注意力负责"组织输出"——基于已生成内容决定下一个词;Cross-Attention 负责连接输入输出——让生成过程能够回溯原始输入。理解这三种注意力的区别,是掌握 Transformer 架构的关键。
机器翻译是 Transformer 的原始应用场景,以英语到中文的翻译为例,输入是 "The cat sat on the mat",输出期望是 "猫坐在垫子上"。
编码阶段,编码器的自注意力层会建立输入词之间的依赖关系网络。处理 "sat" 这个词时,它的 Query 会与 "cat"(主语)、"mat"(宾语)计算高注意力权重,同时也会关注 "on"(介词)来理解位置关系。这种交互的结果是,编码器输出的每个位置不仅包含原始词义,还融合了其在句子中的语法角色和语义上下文。编码器处理完成后,每个 token 的表示都是上下文丰富的——"sat" 的表示中已经编码了"谁坐在哪里"的信息。
解码阶段,解码器需要逐词生成中文翻译。生成第一个字"猫"时,解码器自注意力只能看到之前生成的(实际上还没有内容,只有起始符),因此主要依赖 Cross-Attention。解码器的 Query 会"扫描"编码器输出的所有位置,发现与英语 "cat" 的匹配度最高,从而将 "cat" 的信息提取出来指导生成"猫"。
生成第二个字"坐"时更有趣。解码器自注意力可以看到已经生成的"猫",这提供了重要的上下文约束——模型知道正在生成与猫相关的动作。Cross-Attention 则会去编码器中寻找对应的动词,发现与 "sat" 的关联最强。两种注意力的配合确保了生成的准确性:自注意力保持生成的连贯性,Cross-Attention 确保与原文的对齐。
继续生成"在"字时,解码器自注意力看到"猫坐"两个已经生成的字,知道接下来应该是一个位置信息。Cross-Attention 查询编码器,发现与英语介词 "on" 的匹配度高。生成"垫子"时类似,自注意力确保"垫子"作为"坐"的宾语出现,Cross-Attention 从编码器的 "mat" 获取具体词汇信息。
从注意力可视化可以看到,编码器自注意力形成了密集的交互模式(每个词都关注多个其他词),解码器自注意力则呈现下三角结构(当前词只关注之前生成的词),而 Cross-Attention 会形成清晰的跨语言对齐模式(中文字词与对应的英语词之间有强连接)。这三种模式的组合,使得 Transformer 能够准确理解源语言、生成目标语言,并保持两者之间的对齐关系。
位置编码
自注意力机制本身是顺序不变的——打乱词序后,注意力计算的统计特性不变。这对 NLP 来说是个问题,因为语序显然包含重要信息。Transformer 通过位置编码注入位置信息。
原论文采用正弦-余弦编码方案:偶数维用
后来的工作提出了多种改进方案。BERT 使用可学习的位置嵌入,简单直接但缺乏外推能力;T5 使用相对位置编码,显式建模位置间的相对距离;RoPE(旋转位置编码)通过旋转变换将位置信息注入 Q 和 K,在长文本场景下表现优异,被 LLaMA 等模型采用。
位置编码的选择影响训练稳定性和长文本处理能力。固定编码收敛更快,可学习编码更灵活但需要更多调参;相对位置编码在处理超长文本时更有优势。
残差连接
每个 Transformer 子层后都紧跟着残差连接和层归一化,结构为
残差连接的核心思想是让网络学习"残差"而非直接学习目标函数,如果最优变换接近恒等映射,网络只需将权重置零即可。这种设计极大缓解了深层网络的梯度消失问题——梯度可以直接通过恒等连接传回前面的层,无需经过多次矩阵乘法。信息流动层面,残差连接提供了"高速公路",让原始表示能够直接传递到高层,确保浅层学到的低级特征不会被深层的变换完全覆盖。
层归一化的作用是稳定训练。与批量归一化(BatchNorm)不同,LayerNorm 对每个样本独立计算均值和方差,不依赖批量大小,这使得它非常适合处理变长序列和分布式训练。LayerNorm 将每个位置的表示归一化到相似的数值范围,防止梯度在深层网络中爆炸或消失,加速模型收敛。
Pre-Norm 与 Post-Norm 的选择在工程实践中影响显著。原始 Transformer 使用 Post-Norm(先做子层变换,再加残差,最后归一化),这在浅层网络(6 层)中工作良好,但当网络加深到 24 层、32 层甚至更多时,Post-Norm 会导致训练不稳定——梯度要经过多次子层变换才能回流,数值容易失控。Pre-Norm 将 LayerNorm 移到残差连接之前,即
残差
在 IT 开发和深度学习中,“残差”(Residual) 的字面意思是“剩下的部分”或“偏差”。
在数学表达式
这里的
- 传统网络 (无残差):你给工人一块木头,要求他直接雕刻出一尊佛像。工人必须从零开始,每一刀都不能错,且每一层(工序)都要负责最终形态的成型。如果工序太深,后面的工人可能会毁掉前面工人的心血。
- 残差网络 (Residual):你给工人一块木头,但这块木头已经初具佛像轮廓(这就是输入 )。工人的任务不再是刻出佛像,而是在现有轮廓上修补细微的偏差(这就是残差 )。
前馈网络
每个 Transformer 层除了注意力机制外,还有一个位置无关的前馈网络(Feed-Forward Network,FFN)。标准的 FFN 结构是两层全连接:第一层将维度从
这种"扩展-压缩"结构看似简单,实则精妙。扩展层增加了模型的容量,让每个位置有足够的维度来存储和变换信息;压缩层迫使网络学习高效的表示,将重要特征编码到有限的空间中。从信息论角度看,FFN 相当于对每个位置的特征进行编码-解码过程,这种非线性变换是模型表达能力的关键来源。如果只有注意力而没有 FFN,Transformer 将退化为线性模型。
激活函数的选择影响 FFN 的效果。ReLU 是最简单的选择,计算高效,但存在"死亡 ReLU"问题——负值区域梯度为零,神经元可能永久失活。GELU(Gaussian Error Linear Unit)是概率性的激活函数,定义为
从角色分工看,注意力机制负责"信息交互"——通过 Q、K、V 的计算让不同位置的信息相互聚合,捕捉跨位置的依赖关系;FFN 负责"信息变换"——对每个位置独立进行非线性映射,学习复杂的特征变换。注意力让模型"看到"上下文,FFN 让模型"理解"上下文,两者配合使得 Transformer 既能捕捉长距离依赖,又能学习深层次的语义表示。
参数效率方面,FFN 占据了 Transformer 模型参数量的主要部分(约 2/3),而注意力层只占约 1/3。这种参数分配在实践中证明是合理的:注意力需要捕捉复杂的交互模式,但可以通过多头机制共享参数;FFN 需要为每个位置学习独立的变换函数,因此需要更大的容量。现代 LLM 中,FFN 的隐藏层维度通常设为模型维度的 4 倍,这个比例在效果和效率之间取得了良好平衡。
架构变体与应用
Transformer 的灵活性催生了三种主要架构范式。
- 仅编码器架构以 BERT 为代表,使用掩码语言模型预训练(随机遮盖 15% 的词让其预测),擅长理解类任务如文本分类、命名实体识别、问答。
- 仅解码器架构以 GPT 系列为代表,采用自回归语言模型训练(预测下一个词),适合生成类任务如文本生成、对话、代码创作。

- 编码器-解码器架构如 T5、BART,完整保留了原始结构,在机器翻译、文本摘要等序列到序列任务上表现出色。
这个分类在实践中很重要。选择架构时要考虑任务特性:需要双向上下文的选 BERT 类,需要生成能力的选 GPT 类,输入输出不对称的选 Encoder-Decoder。值得注意的是,现代大语言模型(GPT-4、Claude、LLaMA)几乎都采用 Decoder-Only 架构——这种简化在大规模预训练下反而效果更好,且工程实现更简洁。
// TODO: bert和gpt分支的架构
工程实践中的考量
Transformer 的
位置编码的选择也影响工程实践。固定编码无需额外参数,但可学习编码在某些任务上效果更好。相对位置编码处理变长序列更鲁棒,但实现复杂度更高。RoPE 在长文本场景下表现优异,是目前的主流选择。
训练稳定性是另一个关键点。Transformer 对超参数较敏感,学习率 warm-up、梯度裁剪、LayerNorm epsilon 等细节都需要精心调优。混合精度训练(FP16/BF16)能显著加速,但需要处理数值稳定性问题;分布式训练时,张量并行、流水线并行、数据并行的组合使用是大规模训练的必备技能。
与 RNN/LSTM 的对比
从实际应用角度总结三种架构的差异:RNN 早已被淘汰,其串行计算和梯度消失问题在工程上无法接受;LSTM 在某些对延迟敏感、序列长度可控的场景下仍有价值(如实时语音识别),但新项目基本不会采用;Transformer 已成为标准架构,尽管有
特别值得注意的是,Transformer 的可扩展性催生了"规模即能力"的发现——通过增加参数量、数据量、计算量,模型会涌现出预训练时未明确教给它的能力(如上下文学习、思维链推理)。这既是技术突破,也带来了新的工程挑战:如何高效训练超大规模模型、如何评估模型能力、如何确保安全性。
前沿趋势
从研究趋势看,Transformer 仍在演进。理解 Transformer 的设计思想,是跟进这些前沿工作的基础。
- Mixture-of-Experts(MoE)架构通过稀疏激活降低计算量(如 Mixtral 8x7B);
- 状态空间模型(如 Mamba)试图在保持线性复杂度的同时逼近 Transformer 的表达能力;
- 长上下文技术(如 Ring Attention、滑动窗口)将有效上下文扩展到百万 token 级别;