Vision Transformer
Vision Transformer(ViT)由 Google 在 2020 年提出,其核心思想简洁而深刻:既然 Transformer 在 NLP 领域大获成功,为什么不直接把图片当成一串"单词"来处理呢?这种想法打破了 CNN 在计算机视觉领域的长期统治地位,更重要的是,它为后续的多模态大模型奠定了统一的架构基础。
从 IT 开发者的视角理解 ViT,关键在于掌握它如何将二维图像张量转化为一维序列张量,以及这种转化带来的工程价值。
网络架构总览
ViT 的架构设计非常"工程化",抛弃了 CNN 复杂的滑动窗口和池化层,转而采用高度标准化的堆叠结构。整个网络可以分为四个核心模块:Patch Embedding(数据预处理)、Transformer Encoder(特征提取主干)、CLS Token(全局汇总)以及 MLP Head(输出层)。
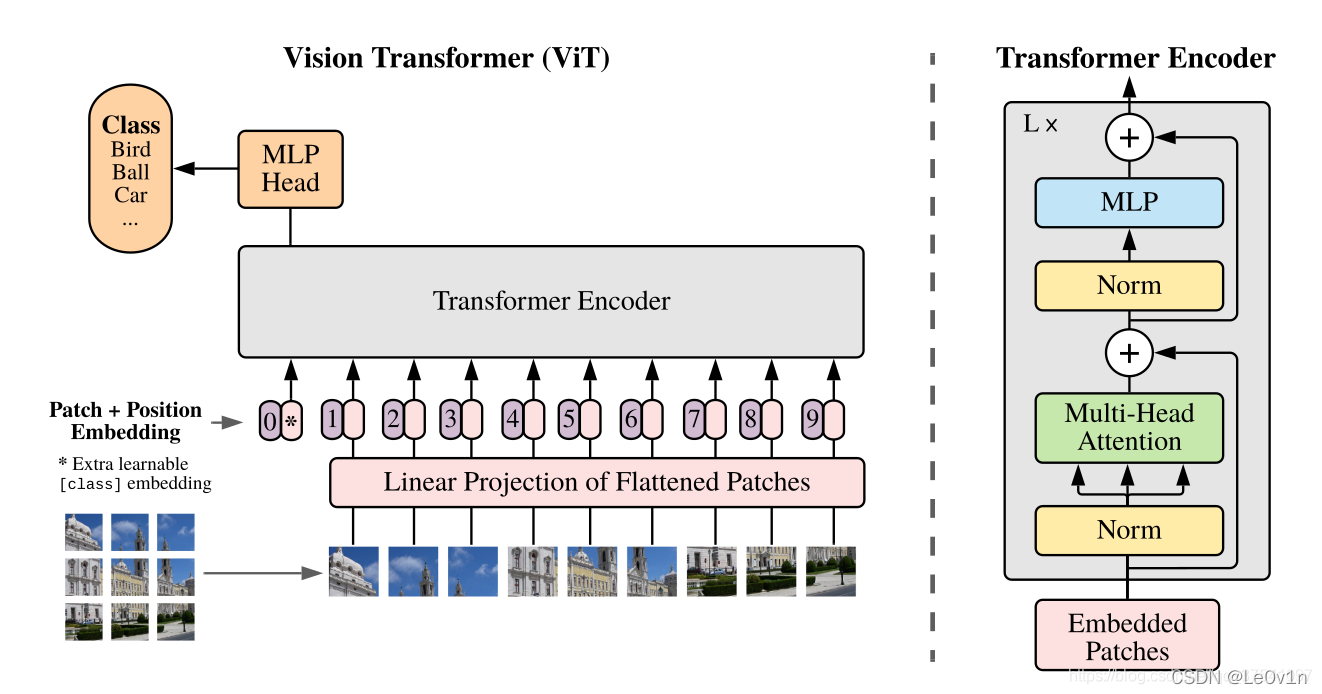
Patch Embedding
这是将 2D 图像转化为 1D 序列的关键步骤。Transformer 无法直接处理 H×W×C 的 3D 张量,因此 ViT 首先将图像切分为固定大小的 Patch(例如 16×16)。假设输入图像为 224×224,Patch 大小为 16,则会得到 (224/16)² = 196 个 Patch。
在代码实现中,这一步通常通过一个 stride 和 kernel_size 都等于 Patch Size 的 Conv2d 层来实现。每个 Patch 被打平(Flatten)并通过线性层映射到维度 D(ViT-Base 中 D=768)。这种实现方式计算效率极高,本质上是用卷积核在图像上滑动,提取局部的视觉特征。
CLS Token 与 Position Embedding
CLS Token 模仿 BERT 的设计,在序列开头插入一个可学习的向量。最终分类任务只取这个 Token 对应的输出,它不负责表达图像的具体局部细节,只负责在全局注意力机制下"旁听"所有图像块的信息,并最终给出总体的语义判断。这种设计避免了从所有 Patch 输出中取平均值的模糊性,给模型一个专门的全局决策入口。
由于 Transformer 的 Self-Attention 是置换不变的(它不知道 Patch 之间的相对位置),必须手动加入位置信息。ViT 通过创建一个可学习的参数矩阵,直接加到 Patch Embedding 向量上实现位置编码。这里的加法是逐元素相加,不改变维度。
Transformer Encoder
这是模型最吃算力的部分,由多个完全相同的 Block 堆叠而成(ViT-Base 有 12 层)。每个 Block 包含 LayerNorm、Multi-Head Self-Attention(MSA)、MLP(Feed Forward)以及残差连接。LayerNorm 在进入算子前进行归一化保证训练稳定性,MSA 负责 Patch 之间的全局相关性计算,MLP 负责对单个 Patch 的特征进行非线性变换,残差连接 x=x+Sublayer(x) 防止梯度消失。
核心技术洞察
架构统一的价值
ViT 的真正价值不仅是性能(在超大规模数据下),更是工程上的大一统。在 ViT 普及之前,多模态模型通常像一个"缝合怪":视觉端使用 CNN 输出空间特征图,语言端使用 Transformer 输出 Token 序列。由于 CNN 和 Transformer 的数学特性完全不同,对齐变得非常痛苦。
ViT 出现后,图像被切成 Patch,本质上变成了"视觉单词",两边都用同样的 Transformer Block。这种同构性使得对比学习和交叉注意力的计算变得极其自然。在 CLIP 或 BLIP 这样的模型中,图像和文本最终都被映射到相同的 D 维向量空间,可以直接计算余弦相似度,或者直接拼接后输入给下一个 Transformer 层。
从底层工程角度看,统一架构意味着优化难度降低——只需要针对 GEMM(矩阵乘法)进行极致优化,就能同时加速视觉和语言处理。在 C++ 端使用 LibTorch 或 TensorRT 部署时,只需要实现一套标准的 Transformer 推理算子。
MLP 层的作用
如果说 Attention 负责让模型"看"到全局相关性,那么 MLP 就负责对每个位置的特征进行非线性变换和知识提取。在 ViT 中,MLP 块通常由两个全连接层和一个 GELU 激活函数组成:Linear 1 将输入维度 D 映射到 4D,GELU 引入非线性,Linear 2 将维度从 4D 重新映射回 D 以便进行残差连接。
理解 MLP 的关键在于它的"局部性":MLP 独立地作用于每一个 Patch(或 Token),它并不关心 Patch 之间的位置关系,只处理当前这个 Patch 内部的特征维度。如果输入张量形状是 [Batch, Tokens, Dimension],MLP 的矩阵乘法只作用在最后的 Dimension 上。由于各 Token 之间互不干扰,MLP 在 GPU 上具有极高的并行计算效率。
Attention 负责"聚合"来自其他 Patch 的信息,而 MLP 负责对聚合后的信息进行"消化"和"加工",学习更复杂的特征组合。Transformer 约 2/3 的参数量实际上都集中在 MLP 层,它更像是一个存储模型"知识"的地方。
Token 的概念演变
在 ViT 架构中,图像不再被看作像素的点阵,而是被看作一系列视觉块。将一张图片切分成固定大小的方块(例如 16×16 像素),每一个方块经过线性映射后变成的一个向量,就称为一个 Token。它代表了图像中某一特定区域的局部特征(颜色、边缘、纹理等)。
NLP 中的 Token 是从预定义的词典中"选"出来的,通过查表获得向量;而图形中的 Token 是从原始像素中"算"出来的,通过对 Patch 进行线性变换直接生成向量。这种"万物皆可 Token"的思想,正是目前大模型能够处理图、文、视频甚至音频的技术基石。
工程实践考量
训练与推理的参数传递
在推理阶段,参数是只读的。假设输入图像为 224×224×3,Patch 大小为 16,数据流经过 Patch Embed(输出 [1, 196, 768])、Concat CLS([1, 197, 768])、Pos Embed([1, 197, 768])、Transformer Layers([1, 197, 768])、Extract CLS([1, 768])、MLP Head([1, 1000])六个步骤。
训练阶段不仅有前向传播,还涉及梯度的计算与存储。每一层都维护着 Weight(权重)和 Gradient(梯度)两个关键张量。优化器(如 AdamW)根据梯度更新各层的权重。Dropout 在前向传播中随机将部分神经元置零防止过拟合,推理时该层失效。LayerNorm 在训练时计算当前 Batch 的均值和方差,推理时使用训练阶段累计下来的全局统计量。
如果你在底层实现 ViT 的推理引擎,由于 Transformer 各层的输入输出 Shape 完全一致,可以使用 Ping-Pong Buffer 进行内存复用,极大地节省显存开销。
Patch Embedding 层的参数
这是一个非常关键的细节:Patch Embedding 层的参数与 CLS Token 是两个完全独立的部分。Patch Embedding 层是"转换工具"(算子参数),而 CLS Token 是"数据输入"(可学习变量)。
Patch Embedding 通常由一个 Conv2d 实现,其参数包括卷积核权重(维度 [D,C,P,P])和偏置项(维度 [D])。以 ViT-Base 为例,参数量为 768×3×16×16 + 768 ≈ 59 万。这些参数是共享的,同一个卷积核扫过全图所有 Patch。
CLS Token 则是一个独立的可学习参数,维度为 [1,1,D],参数量仅为 768。整个序列只有一个 CLS Token,在训练开始时随机初始化,在反向传播时数值会被更新。
ViT 与 NLP Transformer
理解 ViT 的另一种重要视角是与 NLP 中的 Transformer 进行对比。ViT 本质上是将 NLP Transformer 的架构迁移到视觉领域,但两者在输入表示、位置编码、注意力模式等方面存在显著差异。
输入表示的根本差异
NLP Transformer 处理的是离散的 Token 序列。原始文本经过分词器被切分为单词或子词,每个 Token 被转换为整数索引,然后通过 Embedding Lookup 从词表中获取对应的向量表示。这个过程本质上是一个查表操作,词表大小通常是固定的(如 BERT 的 30522 个词)。Token 的语义是天然的,每个单词本身就携带了明确的语言含义。
ViT 处理的是连续的图像像素。图像不具备天然的分词边界,需要人为地将其切分为固定大小的 Patch(如 16×16)。每个 Patch 包含 256(16×16)个像素点,通过线性投影转化为向量表示。这个过程是一个计算操作,通过卷积核权重对像素进行变换。图形 Token 的语义是隐含的,单个 Patch(如一片蓝天)本身没有明确含义,需要通过模型学习才能理解。
这种差异导致了信息密度的不同。NLP 中的一个单词往往代表一个完整的概念,语义密度高;而图像中的一个 Patch 只包含局部纹理信息,语义密度低。这就是为什么 ViT 需要更深的网络和更多的数据来学习视觉特征,而 NLP 模型相对更容易从文本中捕获语义关系。
位置编码的设计差异
位置编码是两者的共同需求,因为 Self-Attention 机制本身不具备位置感知能力。但实现方式有所区别。
原始 NLP Transformer(如 Transformer、BERT)使用正弦余弦位置编码。这是一种固定的编码方式,通过不同频率的正弦余弦函数生成位置向量,使得模型能够学习到相对位置关系。这种设计的优势是可以外推到训练时未见过的序列长度,缺点是位置编码是固定的,无法根据任务调整。
ViT 采用可学习的位置编码。每个位置对应一个可学习的向量参数,随模型一起训练优化。这种设计更加灵活,模型可以根据任务学习最适合的位置表示。但缺点是无法外推,如果输入分辨率变化,位置编码需要重新插值或从头训练。
GPT 等生成式模型则不使用绝对位置编码,而是使用相对位置编码或旋转位置编码(RoPE)。这使得模型在处理变长序列时更加自然,也是现代 LLM 的主流选择。
注意力模式的差异
NLP Transformer 的注意力通常是双向的(BERT)或单向的(GPT)。BERT 使用双向注意力,每个 Token 可以看到所有其他 Token,适合理解任务;GPT 使用因果掩码,每个 Token 只能看到它之前的 Token,适合生成任务。这种设计是由语言的单向性决定的:文本是从左到右生成的。
ViT 的注意力始终是双向的。图像没有自然的方向性,左上角的像素和右下角的像素之间不存在"先后"关系。因此 ViT 中的所有 Patch 都可以相互 attend,这使得模型能够充分捕获全局空间关系。
但全局注意力也带来了计算复杂度问题。NLP 中序列长度通常较小(512 或 1024),而图像切成 Patch 后序列长度可达 196(224×224 图像)甚至更多。为了降低计算量,NLP 中常用的稀疏注意力模式(如 Longformer、BigBird)在视觉领域也获得了应用,Swin Transformer 就是通过局部注意力实现了线性复杂度。
归纳偏置的差异
NLP Transformer 依赖语言的归纳偏置。语言的统计特性很强:某些词经常一起出现,句法结构相对固定,词序变化对语义影响显著。这些先验知识使得 Transformer 能够从相对较少的数据中学习语言模式。
ViT 几乎没有视觉归纳偏置。图像中的统计特性不如语言明显,局部特征可以平移,但语义理解需要全局上下文。ViT 不假设相邻 Patch 相关,也不假设局部特征可以共享权重,所有关系都从数据中学习。这使得 ViT 需要更多数据,但也赋予了它更强的泛化能力。
从模型容量的角度看,NLP Transformer 的参数主要集中在 Embedding 层(词表大小×维度)和 Attention 层。而 ViT 的参数分布更加均匀,Patch Embedding、Attention、MLP 都有相当数量的参数。这种差异反映了模态的特性:语言的词汇是离散且有限的,而图像的特征是连续且无限的。
多模态融合的意义
ViT 与 NLP Transformer 的架构统一性带来了多模态融合的红利。在 CLIP 模型中,图像 ViT 和文本 Transformer 的输出都是形状为 [Batch, D] 的向量,可以直接计算相似度。在 LLaVA 等多模态大模型中,ViT 的输出可以直接作为输入 Token 传递给 LLM,无需复杂的特征对齐。
这种统一性降低了多模态系统的复杂度。在视觉问答任务中,图像和文本可以共享同一个 Transformer 处理器;在视觉推理任务中,视觉和语言信息可以在同一个注意力空间中交互。从工程角度看,只需要实现一套 Transformer 算子,就能同时处理图像和文本。
ViT 与 CNN
理解 ViT 和 CNN 的差异,本质上是在理解两种不同的设计哲学:CNN 依赖人类的先验知识(局部性、平移不变性),而 ViT 选择让模型从数据中学习一切。
原理层面的本质差异
从信息流动的角度看,CNN 通过层级化的卷积和池化逐步扩大感受野,浅层网络关注局部纹理(边缘、角点),深层网络整合全局语义。这种设计符合人类视觉系统的层次化处理机制,具有很强的归纳偏置。例如,一个 3×3 的卷积核天然假设相邻像素之间存在强相关性,无论图像如何平移,这个局部模式都能被识别。
ViT 则完全放弃了这种假设。它将图像切成 Patch 后,第一层 Self-Attention 就能计算任意两个 Patch 之间的相关性,理论上第一层就能"看到"整张图。这种全局建模能力使得 ViT 更擅长捕获长距离依赖,比如理解图像左上角的文字与右下角的人物之间的关系。但代价是模型必须从海量数据中重新学习那些 CNN 天然就具备的局部特征,这就是为什么 ViT 在小数据集上表现糟糕的根本原因。
从参数分布看,CNN 的参数集中在卷积核和全连接层,不同位置共享相同的卷积核权重,这种参数共享机制极大地减少了模型参数量。ViT 的参数则主要集中在 Attention 的 QKV 投影矩阵和 MLP 层,虽然 Transformer Block 本身可以堆叠复用,但每个位置的特征处理是独立的。这使得 ViT 在相同参数量下,实际的可学习自由度更高,但也更容易过拟合。
感受野与注意力机制
CNN 的感受野是逐步扩大的。以 ResNet-50 为例,第一层卷积的感受野只有 7×7,经过多次卷积和池化后,最终层的感受野才能覆盖整个输入。这种渐进式的设计使得 CNN 能够有效地提取层次化特征,但也限制了模型对全局信息的早期访问。当图像中存在需要全局上下文才能理解的模式时(比如判断一个物体的遮挡关系),CNN 需要等到深层才能获得足够的信息。
ViT 的 Self-Attention 机制使得每个 Patch 在第一层就能与所有其他 Patch 进行交互。这种全连接式的信息流动使得 ViT 特别适合处理需要全局推理的任务。在实际应用中,ViT 在图像分类、目标检测等任务上的表现证明了全局注意力的价值。但也需要注意的是,Self-Attention 的计算复杂度是 O(N²),其中 N 是 Patch 的数量。当图像分辨率增加时,计算量和显存占用会呈平方级增长,这限制了 ViT 在高分辨率图像处理中的应用。
相比之下,CNN 的计算复杂度与图像分辨率呈线性关系,这使得 CNN 在处理高分辨率图像时更具优势。为了解决这个问题,后续的 Swin Transformer 等模型引入了局部注意力机制,通过滑动窗口将全局注意力分解为多个局部注意力,在保持全局建模能力的同时降低了计算复杂度。
数据需求与训练策略
在数据需求方面,CNN 具有明显的优势。由于 CNN 具有强归纳偏置,它在中小规模数据集上(如 ImageNet-1K 的 128 万张图片)就能训练出优秀的模型。ResNet-50 在 ImageNet-1K 上从头训练就能达到约 76% 的 top-1 准确率。
ViT 则完全不同。原始 ViT 论文中的实验表明,在 ImageNet-1K 上从头训练的 ViT 表现远不如 ResNet,甚至会低于 ResNet-50 约 5-8 个百分点。只有在 ImageNet-21K(1400 万张图片)或 JFT-300M(3 亿张图片)这样的超大规模数据集上预训练后,ViT 才能展现出超越 CNN 的性能。这一现象揭示了 ViT 的根本特点:它是一个数据饥渴型的架构,需要海量数据来学习那些 CNN 通过归纳偏置免费获得的先验知识。
从训练策略看,ViT 比 CNN 更依赖于训练技巧。ViT 需要更长训练时间(更多 epoch)、更强的数据增强(如 CutMix、MixUp)、更激进的学习率调度(如 cosine decay with warmup),以及更重的正则化(如更高的 Dropout 率、Label Smoothing)。这些技巧都是为了帮助 ViT 在没有强归纳偏置的情况下,从数据中更有效地学习特征表示。相比之下,CNN 的训练相对简单,标准的 SGD 优化器配合基本的数据增强就能取得不错的效果。
性能对比与适用场景
在 ImageNet 分类任务上,大规模预训练的 ViT-Large 在 ImageNet-1K 上微调后能达到约 88.5% 的 top-1 准确率,超越了同等参数量的 ResNet 模型。但需要注意的是,这种优势建立在 ViT 使用了更多预训练数据的基础上。如果只在 ImageNet-1K 上训练,ResNet 仍然具有竞争力。
在下游任务上,ViT 的优势更加明显。在目标检测、实例分割、语义分割等需要密集预测的任务中,ViT 通过提供更丰富的全局特征表示,往往能够取得比 CNN 骨干网络更好的性能。特别是在处理大物体和复杂场景时,ViT 的全局注意力机制能够更好地捕获物体之间的语义关系。
从推理效率看,CNN 在高分辨率图像处理上仍然具有优势。ResNet-50 处理 224×224 图像的推理时间约为 5ms(在 V100 GPU 上),而 ViT-Base 约为 8ms。当分辨率增加到 384×384 时,ResNet-50 的推理时间增加到约 12ms,而 ViT-Base 则激增至约 35ms。这种差异在高分辨率图像处理场景下(如医学影像、卫星图像)尤为明显。
从部署角度看,CNN 的算子更加多样化,包括各种卷积变体(深度可分离卷积、空洞卷积等),这使得在特定硬件上优化 CNN 需要更多工作。ViT 的算子则更加标准化,主要是矩阵乘法,这使得在支持 Tensor Core 的现代 GPU 上能够获得更好的加速效果。在 TensorRT 等推理框架中,ViT 的优化相对简单,只需要对 GEMM 算子进行极致优化即可。
选择建议
如果你在处理中小规模数据集(百万级别以下),或者需要在端侧设备上部署模型,CNN 仍然是更实用的选择。ResNet、EfficientNet 等成熟的 CNN 架构在精度和效率之间取得了良好的平衡,且有大量预训练权重可供使用。
如果你有海量训练数据(千万级别以上),或者关注多模态应用场景,ViT 及其变体是更好的选择。特别是在需要与语言模型融合的多模态任务中,ViT 的统一架构能够显著降低系统复杂度。对于需要全局推理的视觉任务(如图像问答、视觉推理),ViT 的全局注意力机制能够提供更强的建模能力。
对于高分辨率图像处理任务,可以考虑使用混合架构或局部注意力变体。例如,使用 CNN 进行特征提取后再接 Transformer,或者使用 Swin Transformer 这样的分层 Vision Transformer,在保持全局建模能力的同时控制计算复杂度。
ViT 的核心价值不在于在所有场景下替代 CNN,而在于提供了另一种可能:当数据足够多、算力足够强时,我们可以让模型放下人类的先验假设,从数据中自由学习。这种思想不仅影响了计算机视觉领域,更重要的是为多模态大模型的发展奠定了统一的架构基础。现在的多模态模型(如 LLaVA、Qwen-VL)几乎无一例外地使用 ViT 或其变体作为 Vision Tower。这种趋势证明了:在通往通用人工智能的路上,算法的通用性比特定领域的精细设计更重要。在 C/C++ 端部署时,往往发现跑一个 ViT 比跑一个带有很多自定义算子的 CNN 还要省心,因为算子太标准了。
从工程实践看,ViT 的出现标志着计算机视觉从"手工设计特征"到"学习一切特征"的转变。CNN 代表了人类对视觉理解的经验总结,而 ViT 代表了对数据驱动方法的极致信任。这两种哲学各有千秋,在实际应用中需要根据具体场景和数据条件进行选择。