深度学习
限制机器学习的一大难题在于训练数据的获取,得到大量的优质训练数据是训练成功的前提。如何能够做到优质?那就要对数据做充足的特征工程。深度学习通过多层神经网络架构,极大地简化了特征工程的工作,让机器能够自动学习特征表示,极大推动了连接主义 AI 的发展。
发展时间线
深度学习的发展经历了多次起伏,从早期的理论探索到如今的落地应用,每一次突破都伴随着算法、算力和数据的协同进化。
- 1958 年,Frank Rosenblatt 提出感知机(Perceptron),这是第一个能够学习的神经网络模型。虽然感知机只能解决线性可分问题,但它开创了连接主义的先河。1969 年《Perceptrons》一书指出感知机的局限性(如无法解决 XOR 问题),导致神经网络研究进入第一个寒冬。
- 1986 年,Geoffrey Hinton 等人重新推广了反向传播算法,解决了多层网络的训练问题。这一时期的多层感知机(MLP)在手写数字识别等任务上取得了一定成功,但受限于当时的计算能力和数据规模,神经网络的表现仍无法与传统的支持向量机(SVM)等方法竞争。
- 1998 年,Yann LeCun 提出 LeNet-5,这是现代卷积神经网络(CNN)的雏形。LeNet-5 成功应用于银行支票手写数字识别,证明了卷积结构在图像处理上的有效性。但当时深度学习的概念尚未形成,LeNet-5 更多被视为一种特殊的特征工程方法。
- 2012 年是深度学习爆发的转折点。AlexNet 在 ImageNet 图像分类竞赛中将错误率从 26% 大幅降低到 15%,这个突破性进展震惊了计算机视觉领域。AlexNet 的成功归功于三个因素:ReLU 激活函数缓解了梯度消失,GPU 并行计算提供了算力支持,ImageNet 大规模标注数据集提供了训练基础。自此,深度学习成为人工智能的主流范式。
- 2017 年,Google 团队发表论文《Attention Is All You Need》,提出 Transformer 架构。Transformer 抛弃了当时 NLP 领域主流的 RNN/LSTM 结构,完全基于自注意力机制处理序列。这个架构不仅在机器翻译任务上取得更好效果,更重要的是实现了高度的并行化,使得训练大规模语言模型成为可能。
- 2018 年是预训练语言模型的元年。BERT 通过双向编码和掩码语言建模,在 11 项 NLP 任务上取得突破。GPT-1、GPT-2 则展示了自回归生成的潜力。这些模型证明了"预训练 + 微调"范式的有效性——先在大规模语料上学习通用语言表示,再针对具体任务进行微调。
- 2022 年底,ChatGPT 发布标志着大语言模型正式落地应用。GPT-3.5/4 展示了惊人的对话能力、代码生成能力和推理能力,AI 从实验室走向了普通用户。与此同时,扩散模型在图像生成领域大放异彩,Midjourney、Stable Diffusion 等产品展示了 AIGC 的巨大潜力。
核心思想
深度学习的本质是通过端到端学习(End-to-End Learning)的方式,用数据驱动模型自动提取层次化的特征表示:
- 浅层网络学习低级特征(边缘、纹理、音素)
- 深层网络学习高级特征(物体部件、语义概念)
- 输出层完成最终任务(分类、检测、生成)
这种分层抽象的方式与人类感知系统高度相似,也是深度学习强大表达能力的来源。
感知机
感知机(Perceptron)是机器学习中最古老、最简单的神经网络模型,它是单层神经网络的原型,主要用于二分类任务。感知机试图找到一个线性超平面,将两类样本完全分开(假设数据线性可分)。感知机是现代深度学习的前身,现代神经网络中的单个神经元就是从感知机演变而来。
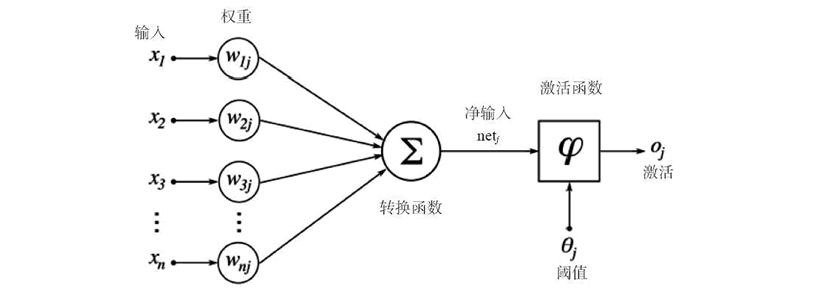
- 模型:
→ 正类。 - 更新:误差驱动
- 在线学习、简单;仅线性可分(XOR问题)、收敛需线性可分数据。
感知机的本质是一个多元函数,该函数对多个输入参数进行加权求和,其中
感知机堆叠
单层感知机的致命缺陷在于只能处理线性可分问题,这限制了它的应用范围。比如经典的 XOR 问题,无法用一条直线将样本分开,但通过堆叠两层感知机就可以完美解决。这个观察启发了一个关键思想:将多个感知机分层连接,每一层的输出作为下一层的输入。
这种堆叠结构就是多层感知机(MLP)的雏形。输入层接收原始特征,隐藏层对特征进行多次变换,输出层给出最终预测。每层包含多个神经元,层与层之间全连接,每个连接都有独立的权重参数。通过增加隐藏层的层数和宽度,网络可以拟合任意复杂的函数,这就是万能逼近定理的理论保证。
但这里有个陷阱:如果只做简单的线性变换堆叠,多层网络等价于单层网络。因为 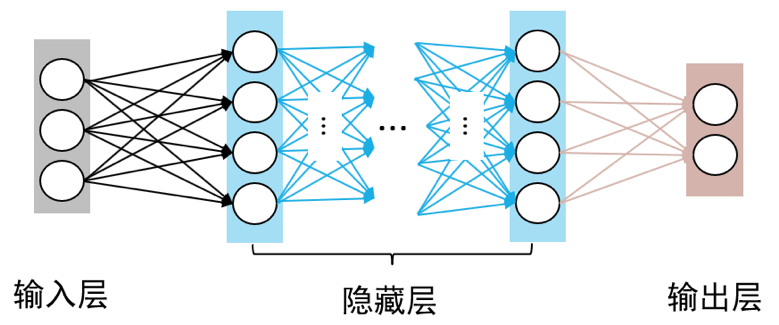
反向传播和梯度下降法,对于这种多层的网格状的模型要如何求导?如何训练呢?此时反向传播的方法应运而生。反向传播法利用逐层求导递推的方式,在训练期间
激活函数
激活函数(Activation Function)是神经元中的关键组件,它为网络引入非线性变换能力。如果没有激活函数,多层神经网络无论有多少层,本质上都只是线性变换的叠加,等价于单层网络,无法解决复杂的非线性问题。
常见激活函数
Sigmoid:
- 输出范围
,适合概率输出 - 问题:梯度消失、计算开销大、输出非零中心
Tanh:
- 输出范围
,零中心化 - 问题:仍存在梯度消失
ReLU:
- 计算简单、缓解梯度消失、稀疏激活
- 问题:神经元"死亡"(负值区域梯度为0)
- 目前最常用的激活函数
Leaky ReLU:
- 解决 ReLU 的"死亡"问题
- 负值区域保留小梯度
GELU:
- Transformer 模型中常用
- 平滑的非线性,性能更好
选择激活函数需要考虑任务特性、网络深度和训练稳定性。现代深度学习中,隐藏层多用 ReLU 或其变体,输出层根据任务选择(分类用 Softmax,回归用线性)。
不可解释性
深度学习模型通常包含数百万甚至数十亿个参数,这些参数通过复杂的非线性变换组合在一起,形成了一个"黑盒"系统。我们很难直观理解模型为什么做出某个预测,哪些特征起了关键作用。
这种不可解释性带来了一些挑战:
- 调试困难:模型出错时难以定位问题
- 信任问题:在医疗、金融等关键领域难以直接应用
- 安全隐患:容易受到对抗样本攻击
- 偏见放大:可能学习并放大训练数据中的偏见
近年来,可解释 AI(XAI)成为重要研究方向,尝试通过注意力可视化、特征归因、概念激活向量等技术来揭示模型的决策过程。
常见网络架构
深度学习的网络架构经过多年演进,形成了针对不同数据类型和任务的专门化结构。理解这些架构的特点和适用场景,是解决实际工程问题的基础。
前馈神经网络(MLP/FNN)
前馈神经网络(Feedforward Neural Network),也称为多层感知机(Multi-Layer Perceptron),是最基础的神经网络结构。网络由输入层、若干隐藏层和输出层组成,信息从输入层向输出层单向传播,层与层之间全连接。
MLP 的优点是结构简单、易于实现,是理解深度学习的起点。但由于参数量随输入维度呈平方增长,MLP 难以处理高维输入(如图像、长文本),且不包含数据的先验结构假设(如图像的局部相关性、文本的顺序依赖)。现代深度学习中,MLP 主要作为其他架构的组件出现(如 Transformer 中的 FFN 层),或者用于处理维度较低的特征向量。
卷积神经网络
卷积神经网络(Convolutional Neural Network)是计算机视觉领域的主流架构,其核心思想是利用数据的局部相关性和平移不变性。CNN 通过卷积核(Filter)在输入上滑动,提取局部特征,通过权值共享大幅减少参数量。
典型的 CNN 包含卷积层(提取特征)、池化层(降维、增强不变性)和全连接层(输出结果)。从 LeNet-5 到 AlexNet,再到 VGG、ResNet、EfficientNet,CNN 架构不断演进:网络变得更深(ResNet 引入残差连接解决训练难题)、结构更高效(MobileNet、ShuffleFace 等轻量化模型)、训练技巧更丰富(Batch Normalization、数据增强)。
CNN 的应用早已超越图像分类,扩展到目标检测(YOLO、Faster R-CNN)、语义分割(U-Net)、图像生成(GAN 的生成器部分)等领域。虽然 Transformer 在视觉领域(ViT)取得了成功,但 CNN 凭借其归纳偏置和工程成熟度,在实际应用中仍然占据重要位置。
循环神经网络
循环神经网络(Recurrent Neural Network)是处理序列数据的主流架构。RNN 通过隐藏状态在不同时间步之间传递信息,理论上能够处理任意长度的序列。但基础 RNN 存在严重的梯度消失问题,难以学习长距离依赖。
长短期记忆网络(LSTM)通过引入门控机制(输入门、遗忘门、输出门)和细胞状态,选择性保留和遗忘信息,有效缓解了梯度消失问题。门控循环单元(GRU)是 LSTM 的简化版本,参数更少但效果相当。在 Transformer 出现之前,LSTM/GRU 是机器翻译、语音识别、文本生成等任务的主流选择。
虽然 Transformer 在大多数序列建模任务上超越了 LSTM,但循环网络在需要流式处理、对延迟敏感的场景(如实时语音识别、边缘设备推理)中仍然有价值。此外,循环结构作为一种归纳偏置,在特定问题上可能比纯注意力机制更高效。
Transformer
Transformer 是当前深度学习最重要的架构,其核心是自注意力机制(Self-Attention)。注意力机制允许模型在处理每个位置时,直接关注序列中的所有其他位置,有效捕捉长距离依赖。
Transformer 架构包含编码器(Encoder)和解码器(Decoder)两部分。原始论文用于机器翻译,但后续工作将其拆分为只包含编码器的模型(如 BERT,擅长理解任务)和只包含解码器的模型(如 GPT,擅长生成任务)。相比 RNN,Transformer 的优势在于:可以并行训练所有位置,通过堆叠层和增加注意力头扩展到大规模参数,通过位置编码保留序列顺序信息。
Transformer 的成功催生了大语言模型(LLM)时代。GPT-3 展示了规模化的威力(1750 亿参数),ChatGPT 证明了人类反馈强化学习(RLHF)对对齐的重要性。此外,Vision Transformer(ViT)将纯 Transformer 架构应用于图像,取得了与 CNN 相当甚至更好的效果。多模态模型(如 CLIP、DALL-E)进一步展示了 Transformer 的通用性。
图神经网络
图神经网络(Graph Neural Network)用于处理图结构数据(如社交网络、分子结构、知识图谱)。不同于图像的规则网格结构,图的节点数量可变、邻居关系不规则,传统 CNN 和 RNN 难以直接应用。
GNN 通过消息传递(Message Passing)机制聚合邻居节点的信息,更新节点表示。常见的变体包括图卷积网络(GCN)、图注意力网络(GAT)、图采样聚合(GraphSAGE)等。GNN 在分子性质预测(药物发现)、推荐系统(用户-物品二部图)、交通流量预测等场景中应用广泛。
随着大语言模型的发展,GNN 与 LLM 的结合成为新趋势,如用 LLM 生成图的文本描述,再用 GNN 进行推理;或将知识图谱注入 LLM 以增强事实准确性。
生成对抗网络
生成对抗网络(Generative Adversarial Network)是深度学习中最具创新性的架构之一,由 Ian Goodfellow 在 2014 年提出。GAN 的核心思想源于博弈论:让两个神经网络相互竞争,一个生成器(Generator)试图制造假数据,一个判别器(Discriminator)试图识别真假,在对抗中双方都变得越来越强。
生成器的任务是从随机噪声中生成逼真的样本(如图像、文本),判别器的任务是判断输入是真实数据还是生成器伪造的。训练过程中,生成器学习如何欺骗判别器,判别器学习如何更准确地区分真假。当达到纳什均衡时,生成器产生的样本与真实数据无法区分,这就是训练的目标。
GAN 的变体极其丰富。DCGAN 将卷积结构引入 GAN,用于图像生成;CycleGAN 能够实现图像风格转换(如马变斑马)而无需成对训练数据;StyleGAN 可以生成高质量的人脸图像,控制图像的各个属性(年龄、表情、姿态)。GAN 在图像生成、图像修复、超分辨率、数据增强等领域都有广泛应用。
与扩散模型和自回归模型相比,GAN 的优势在于生成速度快(一次前向传播即可生成样本),但训练难度大、模式崩溃(Mode Collapse)问题一直是工程实践中的挑战。近年来扩散模型在图像生成任务上超越了 GAN,但 GAN 的对抗思想仍然影响着生成式 AI 的发展。